1. m-원 탐색 트리
1) 특징 : 이원 탐색 트리보다 분기율을 높여 m개 서브트리로 만든 것
① 장점 : 트리의 높이가 감소(특정 노드 탐색시간 감소)
② 단점 : 삽입, 삭제 시 트리의 균형 유지를 위해 복잡한 연산이 필요함
③ 노드 구조 : <n, P0, K1, P1, K2 ,P2, ... , Pn-1, Kn, Pn >
ex) 3-원 탐색 트리
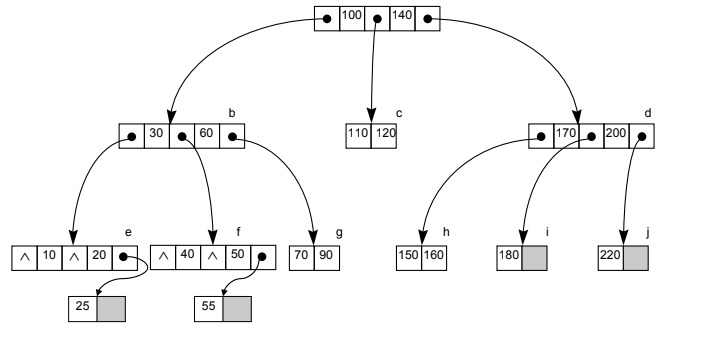
2) m-원 탐색 트리의 검색
- 루트부터 시작하여 찾으려는 노드의 키 인덱스를 증가시키면서 키 값과 찾으려는 키 값이 동일하면 탐색을 멈춘다.
ⓐ 탐색 시간 : 탐색 경로 길이(높이)에 비례
ⓑ 한 노드에는 m-1개 키 값을 저장
ⓒ 높이가 h일 때
- 최대 키 값의 개수: m^h-1 개
- 최소 높이 : logm(n+1)
- 최대 탐색 시간 : O(logm(n+1))
2. B-트리
1) 특징 : 균형된 m-원 탐색트리
ⓐ 루프와 리프를 제외한 내부노드는 m/2~m개의 서브트리를 가지며, m/2-1개의 키값을 가진다.
* 적어도 반 이상은 키가 차야 된다.
ⓑ 노드 구조 : <n, P0, <K1, A1>, P1, <K2, A2>, ... , Pn-1,<Kn, An>, Pn>
ⓒ 장점 : 삽입, 삭제 뒤에도 균형 상태 유지, 저장상태의 효율성
2) 연산
ⓐ 검색 : m-원 탐색 트리의 직접 검색과 같은 과정
- 직접 탐색 : 키 값에 의존
- 순차 탐색 : 중위 순회
ⓑ 삽입 : 항상 리프 노드에 삽입
- 여유 공간이 있으면 순서에 맞게 삽입
- 여유 공간이 없는 경우(overflow, split 발생)
⑴ 해당 노드를 두 개의 노드로 분할
⑵ 중간 키 값을 중심으로 큰 키들은 새로운 노드에 저장, 중간 키값은 부모 노드로 올라가 삽입
ⓒ 삭제
⑴ 삭제될 키 값이 내부노드에 있는 경우
- 이 키 값의 후행(선행) 키 값과 교환 후 리프 노드에서 삭제
⑵ 최소 키 값수(m/2-1) 보다 작은 경우(언더플로우)
- 재분배 : 최소 키 값보다 많은 키를 가진 형제 노드에서 차출
부모노드 키 값을 해당 노드로 이동, 빈자리에 차출된 형제노드의 키 값을 이동
- 합병 : 재분배가 불가능할 경우, 삭제한 후 삭제할려는 노드의 부모노드와 형제노드와 합침. 빈 노드는 제거한다.
* 만약 합쳐졌을 때 오버플로우가 발생하면 분할과정이 필요하고, 양쪽 트리 높이가 달라졌을때 또 그 부모와 형제노드를 합쳐주면 된다.
3. 트라이
1) 특징
- 키를 구성하는 문자나 숫자의 순서로 키 값을 표현한 구조
2) m-진 트라이
- 차수 m : 키 값을 표현하기 위해 사용하는 문자 수(기수)
- 10진 숫자 : 기수가 10이므로 m=10
- m개의 포인터를 표현하는 1차원 배열
- 트라이의 높이 = 키 필드의 길이
- 널 포인터만 가지고 공백노드는 생성하지 않음
- 중복 아이디 조회에 사용
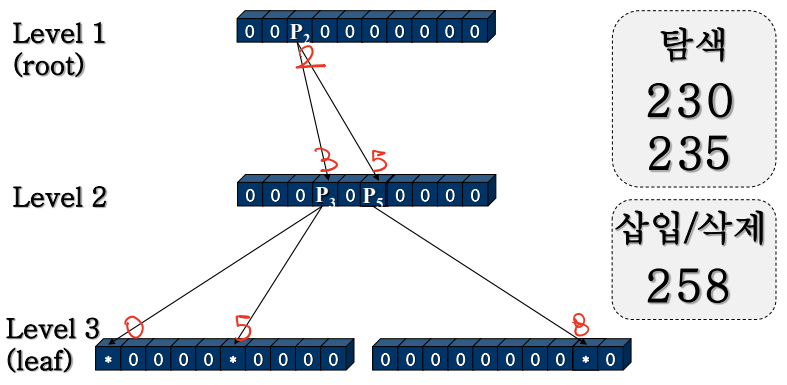
3) m-진 트라이 연산
ⓐ 탐색 : 리프 노드면 성공, 중간에 키 값이 없으면 실패
* 장점 : 균일한 탐색 시간과 없는 키에 대한 빠른 탐색/ 단점 : 저장 공간이 크게 필요
ⓑ 삽입 : 리프 노드에 새 레코드의 주소나 마크 삽입, 없으면 새 리프 노드 생성
ⓒ 삭제 : 노드와 원소들을 찾아서 널 값으로 변경, 노드의 원소값들이 모두 널이면 노드 삭제
'Major > Database' 카테고리의 다른 글
| [파일 처리] 08 직접 화일 (0) | 2022.06.01 |
|---|---|
| [파일 처리] 07 인덱스 된 순차 화일 (0) | 2022.06.01 |
| [파일 처리] 06 인덱스 구조 - 중간고사 전 (0) | 2022.04.15 |
| [파일 처리] 05 화일의 정렬/합병 (0) | 2022.04.13 |
| [파일 처리] 04 순차 화일 (0) | 2022.04.13 |